Spatial Data Science – What is it?
What is data science, and what is a data scientist?
Blog mini-series by Phil Donovan, GBS Spatial Data Scientist
Data science is a term that has burst into many of our lives, both in IT and everyday conversations over the last few years. It is a buzz word which is even buzzing outside of the office boardroom; everyone is talking about the latest ‘machine learning’ algorithm that can predict XYZ. Or a car which can self-drive, an algorithm which is manipulating elections and public opinion, or a government monitoring and classifying people’s actions as good and bad.
Data scientists, it appears, are the wizards (or sorcerers) behind this powerful, modern magic.
This article is a part 1 of a mini-series on spatial data science. Its purpose is to explain what data science is, and what its relationship to the spatial sciences (geography / geospatial information and data) is – otherwise known as spatial data science.
So what is data science?
New Zealand’s very own Hadley Wickham defines data science as a “discipline that allows you to turn raw data into understanding, insight, and knowledge”(1). John Kelleher and Brendan Tierney explain that data science “encompasses a set of principles, problem definitions, algorithms, and processes for extracting non-obvious and useful patterns from large data sets.” In their book, “Data Science” John and Brendan emphasise that the value of data science is in large and complex data sets which humans cannot comprehend by themselves(2). On smaller, human comprehendible data sets, the human mind will nearly always have a stronger understanding of causation and correlation than a computer or machine learning model.
Building on the definitions above, data science includes both data analysis and machine learning. I describe a data scientist as someone that is a data generalist or ‘handyperson’ and someone capable of owning an entire data project – from tidying data, to transforming it with visuals such as plots and graphs, to statistical models, and finally visualisation. The image below is from Hadley’s free book “R for Data Science”(1) and illustrates the workflow of a data scientist:
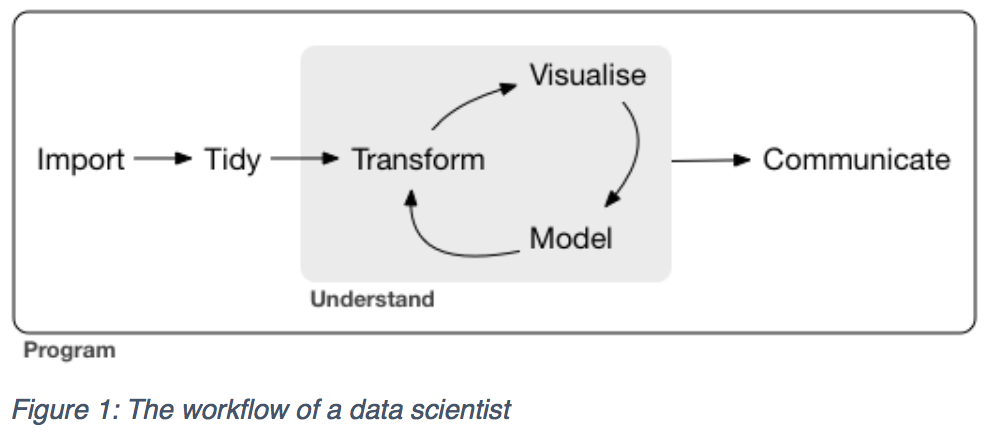
Performing all of these tasks is difficult, and for that reason, they are nearly always encompassed by a programming language such as R, Python and Julia. These languages are specialised in cross-cutting domains and interacting with the numerous components of the ‘data world’ such as web data, SQL databases, Excel spreadsheets, big data stores, machine learning algorithms, etc.
These languages help you automate analysis and ensure that you do not waste time doing things by hand. In using a programming / scripting language, it also means that an analysis is more easily reproducible and transferable. You can think of programming or scripting as a written set of instructions or a recipe for data which is repeatable when required. This recipe is in direct opposition to the visual clicks and mouse points of a Graphical User Interface (GUI) analysis such as what is commonly done in Excel – although not always. In my mind, you should never underestimate the importance of reproducibility as it is a large part of what puts the scientific method and therefore science into the data scientist.
The applications of data science are increasing throughout numerous fields, disciplines and domains. Some of the common applications of data science are in recommender systems such as those found on Amazon, which suggests related commodities such as books based on your previous buying. Other common applications are in credit scoring for loans at banks and fraud detection which pick up on ‘anomalies’ in banking transactions. But what about the spatial applications? Are there spatial data scientists? Yes!
What is spatial data science, and what is a spatial data scientist?
If a data scientist is a data generalist, someone capable of negotiating and bridging the many domains of data analysis and building models of complex data sets, then a spatial data scientist is someone who can do this in the spatial domain. To build on our earlier definition of a data scientist, we now define spatial data science as a discipline that allows you to turn raw spatial data into understanding, insight and knowledge. A spatial data scientist knows how to tidy, transform, visualise, model and communicate spatial data.
But this begs the question, is spatial data special? Or is it just another data type in a table?
In many ways, GIS and spatial data have become less special. GIS is no longer a specialised data type requiring a specialised, dedicated environment such as Esri to perform analysis. Modern data environments such as R, Python, SQLite/Spatialite, PostgreSQL/PostGIS, SQL Server and Oracle all have significant capabilities to store and manipulate data. Figure 2 below illustrates cell phone sites in New Zealand in R which has the point locations stored in ‘geom’ column and expressed in New Zealand Transverse Mercator projection.
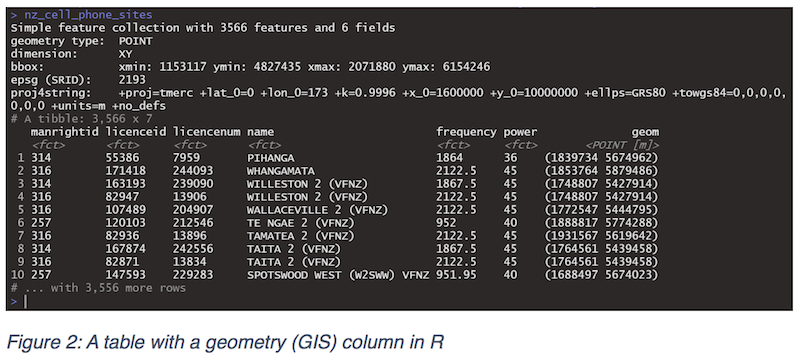
While Figure 2 demonstrates how data science tools and environments are incorporating spatial data, it does not necessarily follow that spatial data, and spatial knowledge are no longer special. It may be more accessible to your everyday data scientist but knowing what to do with this spatial data, the properties of it, and its behaviour when modelling is essential.
For example, recent research demonstrates how badly regular machine learning tools perform on spatial data when they ignore spatial autocorrelation(3). However, it is not just in the modelling phase of analysis that a data scientist could come unstuck. Tidying, transforming, visualising spatial data all take special understandings of the functions and issues surrounding spatial data. From coordinate and projection systems to polygon validity, to geometric functions such as unions, intersections, spatial knowledge is special knowledge. The cartoon from xkcd succinctly encapsulates the potential pitfall of an ignorant application of data science which is a particularly common pitfall in the spatial domain(4).

What can the GIS world learn from data scientists? Why is it important for GIS? Relevance!
As highlighted above, there is a lot to the spatial/GIS world that data scientists need to learn to safely operate. However, there is also plenty for the GIS world to learn from data scientists. Modern data science is very much ‘a science’ and has developed and refined techniques and practices for working with data. These tools, practices and techniques enable the analysis and extraction of insights from data in a highly effective, highly transferable and highly practical way. Tools such as Git and Github enable versioning of analysis, sharing of analysis and simultaneous development of a data-driven project.
Meanwhile, tools such as R and Python are actively developing and implementing a common philosophy of working with data termed ‘tidy data’(5). They’re both constantly evolving and improving the intuitiveness of their API usage both internally and externally.
Pulling it all together
Hopefully, from reading this article you will have gathered some understanding of what data science is, and how spatial data science is similar but still distinctly different to normal data science. In the next post, I will go into detail on what a data scientist is capable of and some exciting applications of spatial data science to show the potential value to your business.
References
- Wickham, Hadley and Grolemund, Garrett. R for Data Science. s.l. : O’Reilly, 2019.
- Kelleher, John and Tierney, Brendan. Data Science. s.l. : MIT Press, 2018.
- Importance of spatial predictor variable selection in machine learning applications — Moving from data reproduction to spatial prediction. Meyer, Hannah, et al. 2019.
- Munroe, Randall. Machine Learning. xkcd. [Online] 2019. https://xkcd.com/1838/.
- Tidy Data. Wickham, Hadley. s.l. : Journal of Statistical Software, 2016.